Code
1 + 1[1] 2Rは、統計分析に強みを持つコンピュータ言語です。
Posit社の提供するオンラインで動く計算環境。Rを便利に使うための装備品。
この講義ではPosit Cloud上でRStudio(統合開発環境;IDE)を動かします。
新しいプロジェクト始める。
一つのプロジェクトの中に複数のRスクリプトやデータをまとめておいておけます。
この講義では一つのプロジェクトを使います。
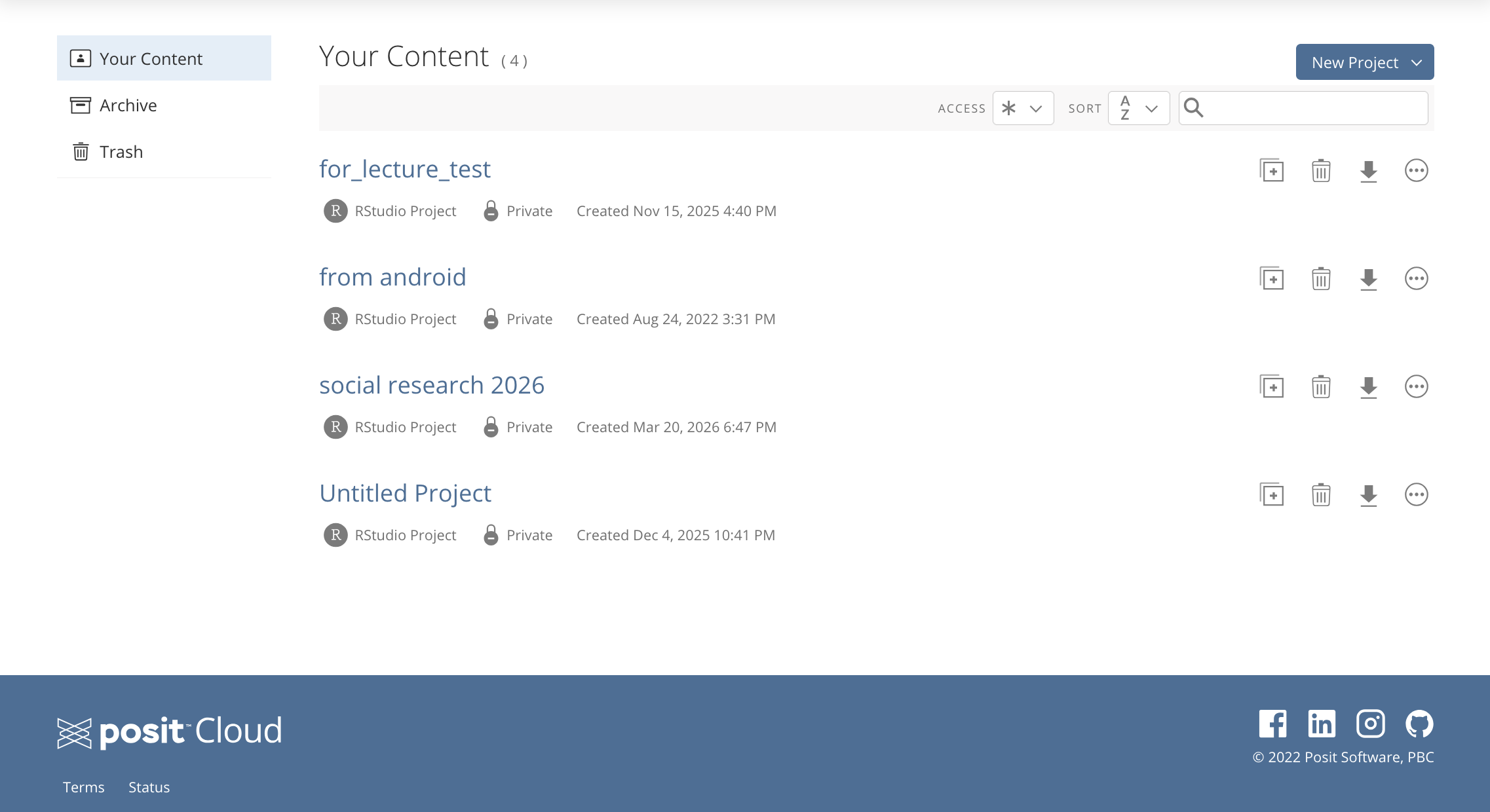
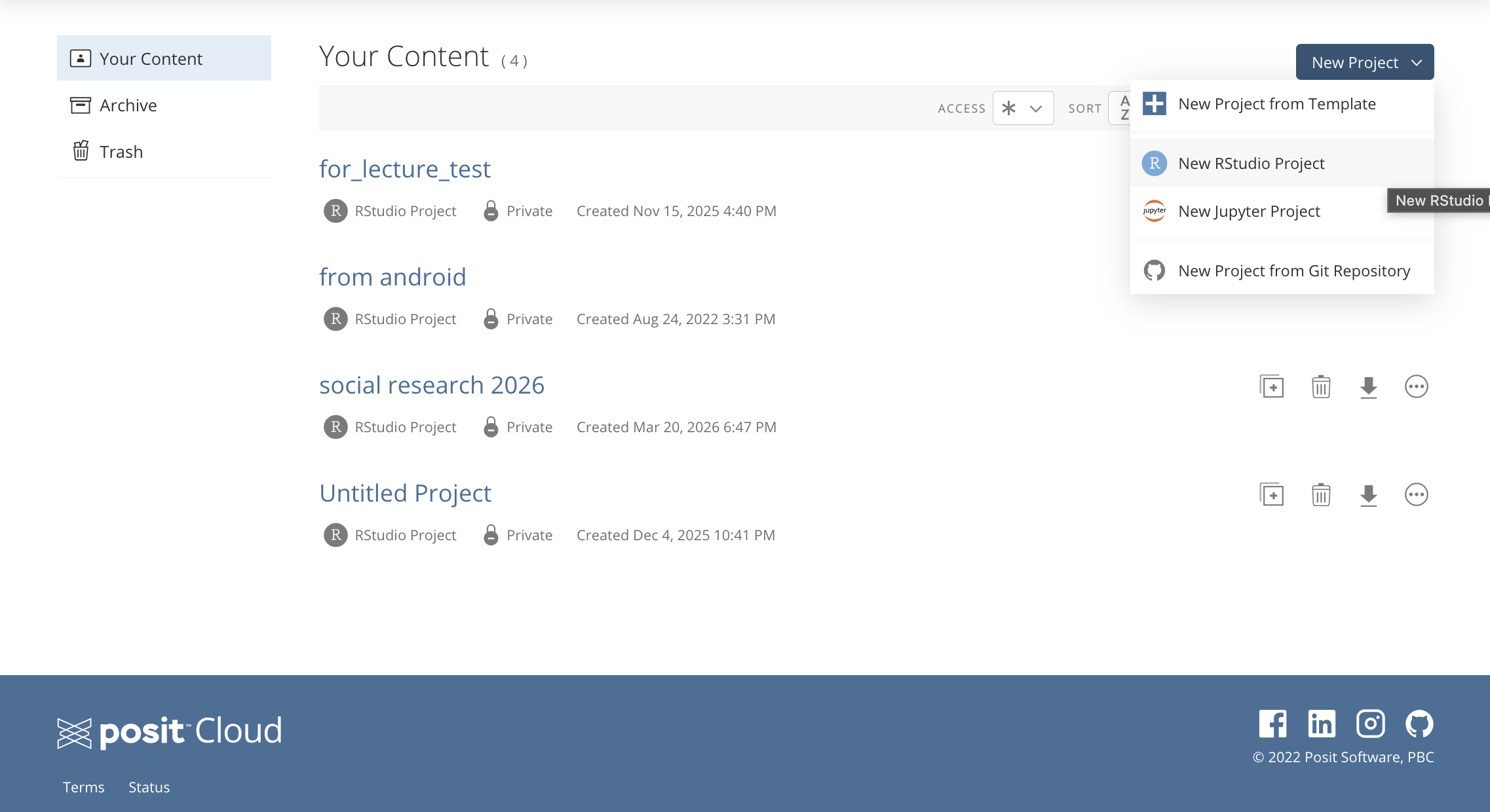
Posit Cloudではログイン後の画面の右上のNew Project ▽から新しいプロジェクトを作成することができます。
ここではNew RStudio Projectを選択します。
プロジェクト内に先にこれから使うデータの保存先を作っておきます。
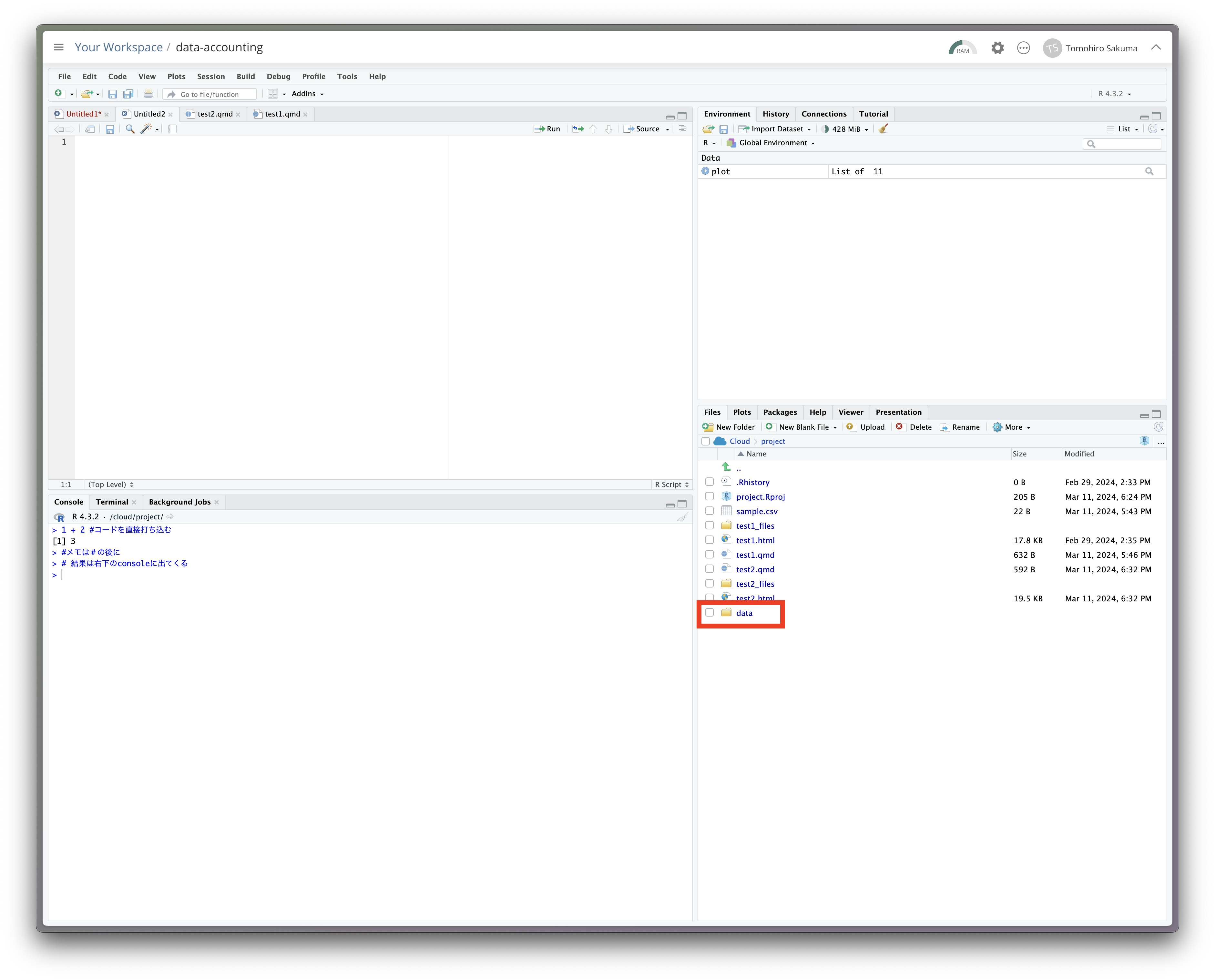
Rなどの統計ソフトを使う利点の一つは、再現性
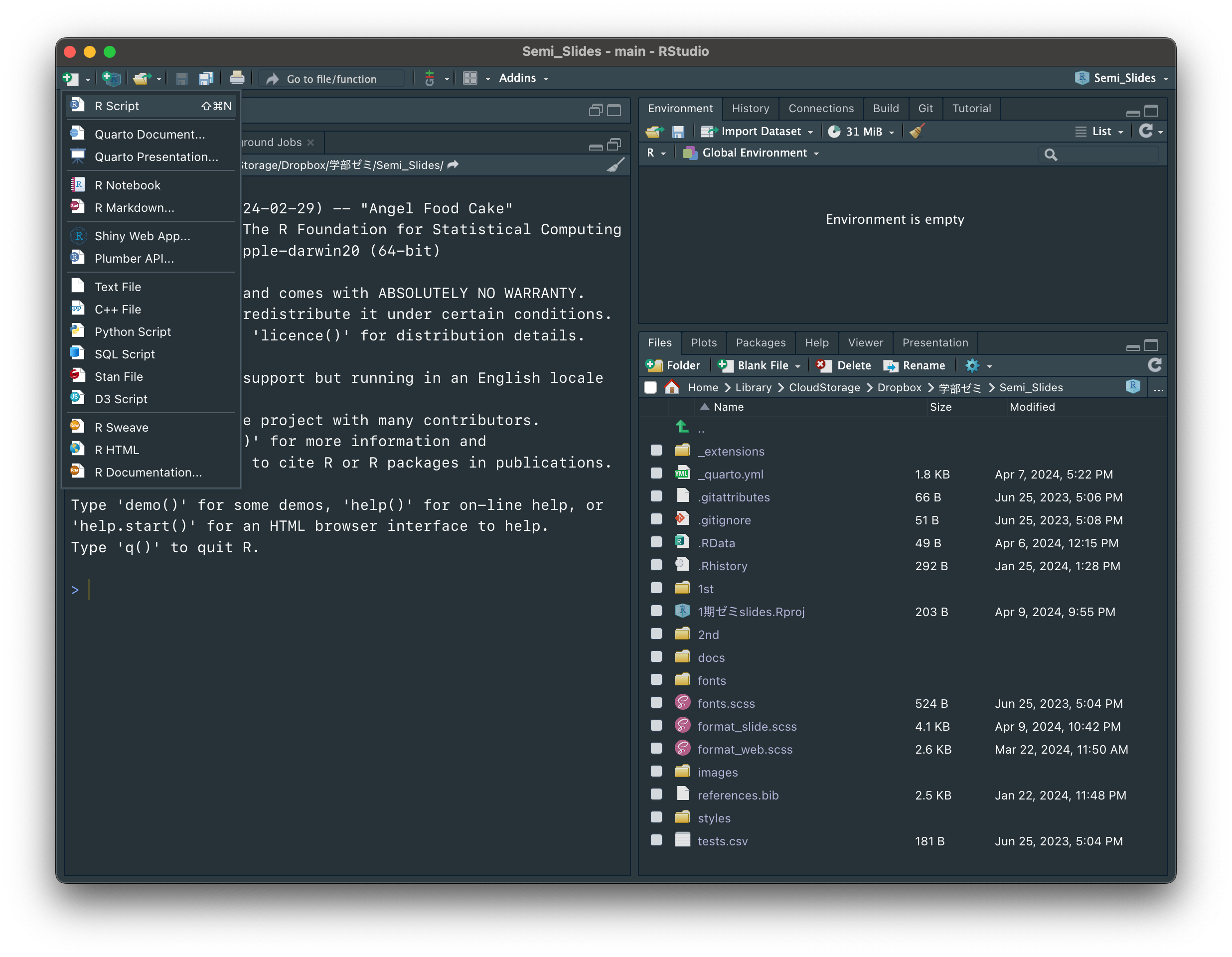
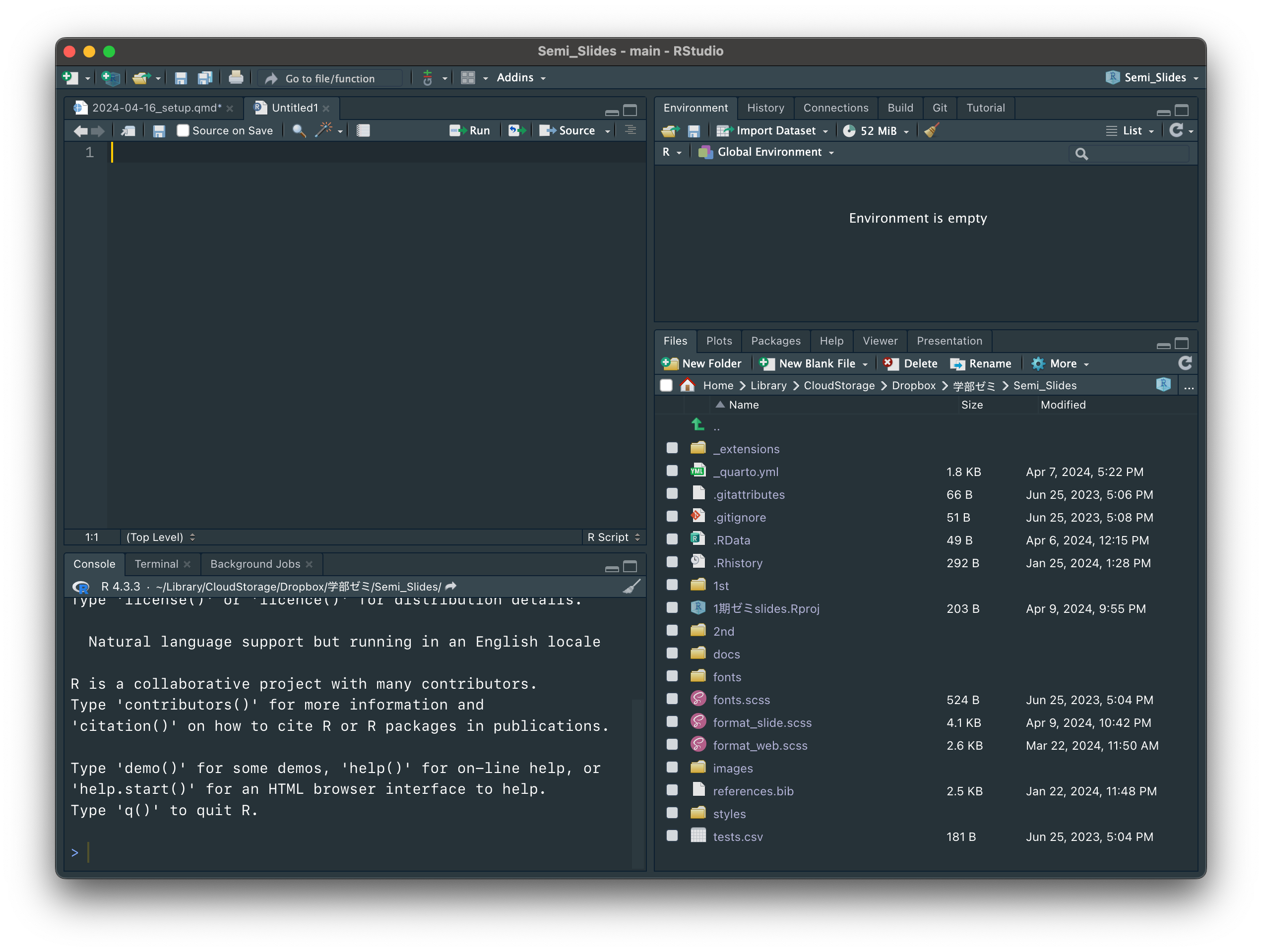
スクリプトファイルは、画面左上にある緑の「+」アイコンを押して、「R Script」を選択することで新規作成できます。
「第2回」という名前をつけて保存してみてください。
ファイルは保存しないと消えます。
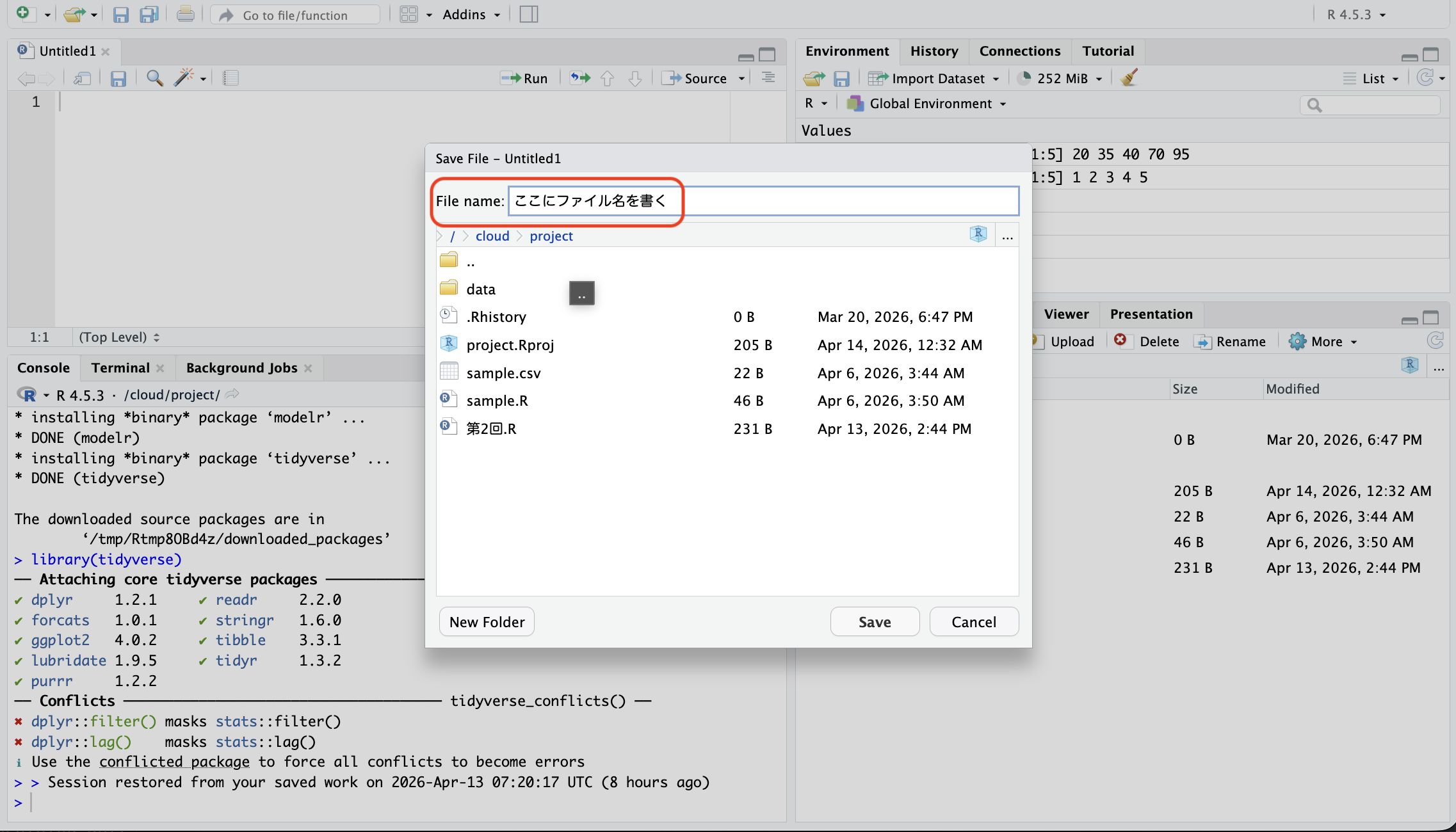
スクリプトファイルを作成すると(初期状態では)画面の左上に白紙のファイルが出てきます。ここにコマンドを打ち込んでいきます。
例えば以下のコマンドを打って実行すると、画面の左下にあるRの画面に実行結果が出ます。
1 + 1[1] 2
実行の仕方は、実行したい行を選択→Ctrl + Enter (Macでは⌘ + Enter)
左下の画面(console)に直接 1 + 1 と打ち込んでも同じ結果が出ますが、後で記録に残らないので、コードはスクリプト画面に書く、左下は結果の表示だけ、と使い分けた方が良いです。
Rスクリプトに以下の内容を打ち込んでください。スクリプト右上のRunボタンを押すか、Ctrl + Enter (Macの場合は⌘ + Enter)で実行してください。
1 + 3
2 * 4[1] 4
[1] 8簡単な計算は、以下の通り
1 + 1[1] 22 * 6 #掛け算は *[1] 122^4 #累乗は ^[1] 16Rでは情報を自分で名前をつけたオブジェクト (変数とも呼ぶ) として保存できます。Rstudioでは、保存されたオブジェクトは右上のEnvironmentというところに表示されます。
x = 3
y = 5
z = x * y「=」の左はオブジェクト、右はその中身を表します。なので、「xという名前のオブジェクトに3を入れる」という指示をしています。これを実行すると画面右上にxというオブジェクトが表示されるはずです。xの中身を確認するには、そのオブジェクトの名前(今回の場合z)を打つと良いです1。
z[1] 15一度オブジェクトを作っておけば、それを使った計算も可能です。
z + 3[1] 18y ^ 2[1] 25文字列でもオブジェクトになります(その場合” “で囲みます)
univ = "Ritsumeikan"
univ[1] "Ritsumeikan"これは数字じゃないので計算はできません
univ + 3Error in `univ + 3`:
! non-numeric argument to binary operator複数の数値の並び(ベクトル)をオブジェクトとすることもできます。
vec = c(1, 2, 3, 4, 5)
vec[1] 1 2 3 4 5ベクトルごと足し算とか掛け算とかもできます
vec + 2
vec * 2[1] 3 4 5 6 7
[1] 2 4 6 8 10縦×横の行列も作れます。matrixという名前です。
mat = matrix(c(435, 165, 265, 135), ncol = 2, byrow = TRUE)
matncol = 2は列の数, byrow = TRUEは、横に並べるということ。
[,1] [,2]
[1,] 435 165
[2,] 265 135例えばbyrow = FALSE にすると縦に並ぶ
mat2 = matrix(c(435, 165, 265, 135), ncol = 2, byrow = FALSE)
mat2 [,1] [,2]
[1,] 435 265
[2,] 165 135縦横の名前をつけると
rownames(mat) = c("行1", "行2")
colnames(mat) = c("列1", "列2")
matrownamesはrow(行)の名前、colnamesはcolumn(列)の名前
列1 列2
行1 435 165
行2 265 135中に入っているものが全て数字なら、計算が可能です。
mat2 = mat + 3
mat2mat2と名付けて保存
列1 列2
行1 438 168
行2 268 138Rを使う上で最も重要なのが関数です。足し算引き算とかよりも高度な命令は関数を使って行います。先ほど作ったベクトル(vec)を使って
mean(vec)
min(vec)
max(vec)[1] 3
[1] 1
[1] 5
上にあるように、Rのコマンドは基本的には、やること(実行する対象)という構造になっている。
mean(vec)は、
mean)vecオブジェクトの中で重要な形式として、データフレームがあります。これは、縦方向に観測値を、横方向に変数を並べたデータを言います。
age = c(18, 21, 22, 23, 34)
gender = c("female", "male", "male", "female", "female")
dframe = data.frame(age, gender)
dframedframeという名前のデータフレームに
エクセル等のデータを読み込んで分析する場合は、このデータフレーム形式です。
データフレームの中の特定の列を指定する場合は、「データフレーム名$列名」
dframe$gender[1] "female" "male" "male" "female" "female"データフレーム内の一部を取り出して関数を使って計算できます
mean(dframe$age)
min(dframe$age)
median(dframe$age)[1] 23.6
[1] 18
[1] 22test_scoreとしてください。mean()関数のに先に作成した点数のベクトルを代入する。Nとしてください。
length()関数はベクトルの次元(長さ)を返します。関数の中には(というかほとんどが)複数の引数を持ちます。
r = seq(from = 0.1, to = 0.2, by = 0.01)seq()は連続した数を作る関数。from = 0.1から、二つ目の引数to = 0.2まで、三つ目の引数by = 0.1ごとに数字を並べる多くの関数は引数の定位置を持っていて、その順番に従った場合、上記のfromやtoといった指示は省略可能です。
r = seq(0.1, 0.2, 0.01)定位置以外の順番でやる場合は、指示が必要です。以下も同じです。
r = seq(to = 0.2, by = 0.01, from = 0.1)Rは半角スペースを無視します。なので、以下は全部同じです
x = c(1, 2, 3) + 3 ^ 2
x=c(1,2,3)+3^2でも、可読性のため、=の前後や2項演算子(+とか-とか)、あとコンマの後などには半角スペースを入れることが一般的です。
Rでは、コンマ(,)の後などコードの切れ目で改行しても動作します。特に()が何重にもなる場合、改行したほうが見やすいかもしれません。例えば、上でやった行列の作成コマンド
mat = matrix(c(435, 165, 265, 135), ncol = 2, byrow = TRUE)は、以下のように書いても全く同じように動作します。
mat = matrix(
c(435, 165, 265, 135),
ncol = 2,
byrow = TRUE
)あまり改行しすぎるのもかえって読みにくいかもしれません。自分が見やすいように程よく改行してください。
mat =
matrix(
c(
435,
165,
265,
135
),
ncol=2,
byrow=TRUE
)より高度なことをしたり、同じことをより簡単にしたりするために追加の機能を足すことができます。
この追加の機能をパッケージといいます。
RがスマートフォンのOSのようなもので、パッケージはアプリのようなもの。


Rのプログラムを格段にわかりやすくするパッケージであるtidyverseを使う準備をしてみます。パッケージは、最初に使う時にはインストールする必要があります(これは1回だけ。App Storeでアプリをとるような感じ)。
install.packages("tidyverse")RStudioであれば右下のPackagesから選択してインストールすることも可能。
パッケージを使う時には、分析ファイルを実行する最初の段階で以下のコマンドを使います(スマートフォンにすでに入っているアプリを開くイメージ)。
library(tidyverse)pacmanパッケージのpacman:::p_load()というコマンドを使うと
library()コマンドを実行して)install.packages()→library())をしてくれます。新しいパッケージを使うたびにインストールしてもらう手間が省けるので、講義ではlibrary()ではなくpacman:::p_load()を使います。
そのための準備として、左下のconsoleに以下のコマンドを打ち込んでください
install.packages('pacman')pacmanがない時library(tidyverse)library(2つめのパッケージ)Error in parse(text = input): <text>:1:10: unexpected symbol
1: library(2つめのパッケージ
^そこで
install.packages('2つめのパッケージ')
library(2つめのパッケージ)とする。
pacmanがある時既にパッケージが入ってるか入ってないかに関わらず(入ってなかったら自動でインストールしてくれる)、しかも複数のパッケージを同時に呼び出せる
pacman::p_load(tidyverse, 2つめのパッケージ)さっきはデータを下記のように手打ちしました。
age = c(18, 21, 22, 23, 34) # 年齢のベクトル
gender = c("female", "male", "male", "female", "female") # 性別のベクトル
dframe = data.frame(age, gender)しかし、アンケートデータや、企業の会計データ等をこのように手打ちするのは現実的ではありません。エクセル等で集計されたデータを読み込むのが一般的です。
以下では、エクセルファイルを読み込む方法についてまとめています。
エクセルで列が変数、行が観測となるようにデータを作られていることを想定します。まず、これを表計算ソフト上でcsv形式でプロジェクト内のdataフォルダに保存します2。
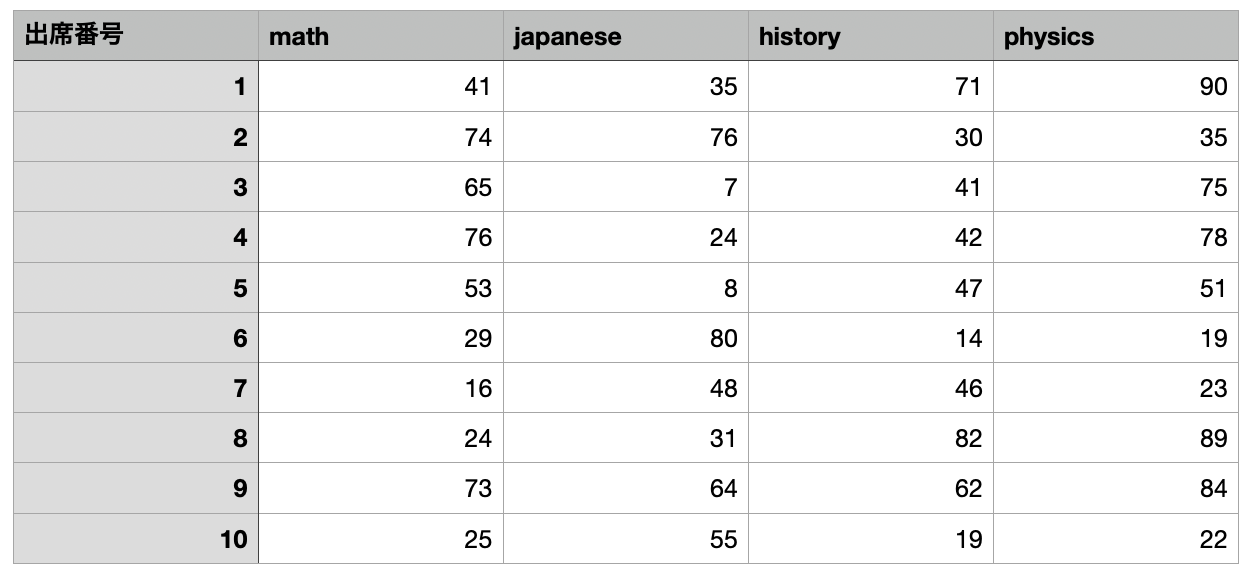
dataフォルダに入れたファイルを読み込むには、csv形式なら、read_csv("ファイル名") もしくはread.csv("ファイル名")を使います3。ここでは、2_tests.csvと言う名前のデータを、testsと言う名前で読み込んでいます。
tests = read.csv("data/2_tests.csv")読み込んだデータを見てみます。最初のいくつかだけが表示されるhead(データ名)コマンドが便利です。
head(tests)現在のデータにはない、4教科の合計点が欲しい。新しい変数はmutate()で作る。ただし、mutateだけだと、変数を作ってどこにも保存してくれないので、保存場所を指定する必要があります。今回は元のデータに付け足す形で作ります。
tests = tests |>
mutate(all = math + japanese + history + physics)tests に testsの中のデータを使って作った新しい変数を入れる。
tests|>パイプ演算子 (|>) は前の情報を次の関数の第一引数に渡すという処理をしてくれます。
例えば、データフレームから一つの列を取り出すときは$ではなく、pullという関数も使えます。
tests |>
pull(math) [1] 41 74 65 76 53 29 16 24 73 25続けて平均値を計算できます。
tests |>
pull(math) |>
mean()[1] 47.6これだけだと mean(tests$math) の方が楽に見えますが、いろいろな処理をしていくときは、|>で繋いだほうが中間オブジェクトが少なくなったり処理が見やすくなったりします。
これだけだと mean(tests$math) の方が楽に見えますが、いろいろな処理をしていくときは、|>で繋いだほうが中間オブジェクトが少なくなったり処理が見やすくなったりします。
tests |>
summarise(
across(
everything(),
mean
)
)プログラミングをやってて一番むかつき、嫌いになる要因はエラーメッセージ
できることは
「エラーが出てたら99.99%自分が悪い(パソコンは悪くない)」ということを自覚すること

Rには分析に必要なさまざまな機能が装備されています。
しかし、
などは、パッケージとして提供されます。その中でもRの操作性全般にわたる改善を行うパッケージがtidyverseです。
tidyverseを使ったコードはいわゆる「モダンな」コードと呼ばれたりします
実際その便利さは、base R (素のR) を知ってないと実感できないですが、この講義では特に断りなくtidyverseの方法を中心に構成しています。
ネットで検索すると、同じ処理でもbase Rを使った方法とtidyverseを使った方法が紹介されることがあります。どっちを使っても、また2つの方法が混ざってても基本的に問題はありません。
Rのコマンドやパッケージは無数にあります。いつも使うもの以外は覚えてられません。
でも大丈夫。ネット上にはさまざまなコマンドの紹介やエラーへの対処法が落ちています。
昔は = がだめで <- を使っていました。今はどちらでも許容されます。細かい部分の違いはありますが、この講義ではどちらを使っても問題は起きないはずです。この講義では、タイプが楽なのとほかの多くの言語でも同じ使われ方をしていることから = を使います。↩︎
エクセル形式で保存されたファイルも読み込めますが、余計な情報が入っていないcsvファイルの方がトラブルが少ない?↩︎
read.csv()とread_csv()は別の関数です (.と_が違う)。read_csv()はtidyverseパッケージに入ってる関数です。こっちの方が色々都合が良いですが、ファイルがとても大きいとかでなかったらどっちを使ってもあまり変わりありません。↩︎